Machine Learning: Analyzing Gender
The Challenge
Machine learning algorithms can contain significant gender and ethnic bias. Where in the machine learning pipeline does bias reside: The input data? the algorithm itself? the types of deployment? More importantly, how can humans intervene in automated processes to enhance and, at least, not harm social equalities? And who should make these decisions?
Importantly, AI is creating the future (technology, i.e., our devices, programs, and processes shape human attitudes, behaviors, and culture). In other words, AI may unintentionally perpetuate past bias into the future, even when governments, universities, and companies such as Google and Facebook have implemented policies to foster equality. So, the big question is: how can we humans best ensure that AI supports social justice?
Method: Analyzing Gender
Gender refers to cultural attitudes and behaviors. Humans function in large and complex societies through learned behaviors. The ways we speak, our mannerisms, the things we use, and our behaviors all signal who we are and establish rules for interaction. Gender is one of these sets of behaviors and attitudes. Ethnicity is another of these sets of behaviors and attitudes.
Gender consists of:
- • Gender Norms consist of spoken and unspoken cultural rules (ranging from legislated to unconscious rules) produced through social institutions (such as families, schools, workplaces, laboratories, universities, or boardrooms) and wider cultural products (such as textbooks, literature, and social media) that influence individuals’ behaviors, expectations, and experiences.
- • Gender Identity refers to how individuals or groups perceive and present themselves, and how they are perceived by others. Gender identities are malleable, change over the life course, and are context specific. Gender identities may intersect with other identities, such as ethnicity, class, or sexual orientation to yield multifaceted self-understandings.
- • Gender Relations refer to social and power relations between people of different gender identities within families, the workplace, and societies at large.
Gendered Innovation 1: Mapping Known Examples of Human Bias Amplified by Technology
Known examples of gender bias
- a. In Google Search, men are five times more likely than women to be offered ads for high-paying executive jobs (Datta, A. et al., 2015).
- b. Google translate has a masculine default. State-of-the-art translation systems like Google Translate massively overuse male pronouns (he, him) even where the text is referring to a woman. Google Translate defaults to the masculine pronoun because «he» is more commonly found on the web than «she» (at a ratio of 2:1). This unconscious gender bias amplifies gender inequality (Schiebinger et al., 2011-2018). When a translation program defaults to «he said» in reference to a woman, it again increases the relative frequency of the masculine pronoun on the web that may reverse hard-won advances toward gender-equal language in human society.
- c. Word embeddings capture associations between words that risk perpetuating harmful stereotypes, such as «man:computer programmer :: woman:homemaker» (Bolukbasi, T. et al., 2016). Word embedding is a popular machine learning method that maps each English word to a geometric vector such that the distance between the vectors captures semantic similarities between the corresponding words. The embedding successfully captures analogy relations such as man is to king as woman is to queen. However, the same embeddings also yield man is to doctor as woman is to nurse, and man is to computer programmer as woman is to homemaker. Taking no action means that we may relive the 1950s indefinitely.
Method: Analyzing Factors Intersecting with Sex and Gender
It is important to analyze sex and gender, but other important factors intersect with sex and gender. This is what scholars call «intersectionality.» These factors or variables can be biological, socio-cultural, or psychological, and may include: age, disabilities, ethnicity, nationality, religion, sexual orientation, etc.
Known examples of ethnic bias
- a. Software used by US courts may be more likely to flag black (as opposed to white) defendants as being at a higher risk of committing future crimes—see discussion on defining fairness below (Angwin, J., & Larson, J. 2016). Solution offered by this paper (Kleinberg et al., 2017).
- b. Searches for black-identifying names result in ads using the word “arrest” more often than searches for white-identifying names, whether or not the person in question has an arrest record (Sweeney, 2013).
- c. Nikon’s camera software is designed not to take a photo if someone is blinking. It misreads images of Asian people as perpetually blinking.
- d. Researchers have deployed convolutional neural networks to identify skin cancer from photographs. They trained their model on a dataset of more than 1.28 million images, 60% of which were scrapped from Google Images (Esteva et al., 2017). But less than 5% of these images are of dark-skinned individuals and the algorithm was not tested on dark-skinned people. Thus the performance of the classifier could vary substantially across different populations.
- e. Growing applications of predictive models in genetic medicine also highlight the danger of data disparities. As of 2016, over 80% of all genetics data are collected from individuals of European ancestry. This means that disease risk predictors may fail dramatically for non-European populations. Indeed, patients of African ancestry are more likely than those of European ancestry to be wrongly diagnosed with increased genetic risk of developing hypertrophic cardiomyopathy—a life-threatening heart condition (Popejoy & Fullerton, 2016).
Known examples of gender intersecting with ethnicity
- a. Commercial facial recognition systems misclassify gender far more often when presented with darker-skinned women compared with lighter-skinned men, with an error rate of 35% versus 0.8%—see also solutions below (Buolamwini & Gebru, 2018).
Gendered Innovation 2: Mapping Solutions
Building training datasets to avoid bias
- a. Several research groups are actively designing “datasheets” containing metadata and “nutrition labels” for machine learning datasets (Gebru et al., 2018; MIT Media Lab, 2018). While the specific form of metadata will depend on the domain, each training set should be accompanied by information on how data were collected and annotated. Data containing human information should summarize statistics on the geography of the participants, their gender and ethnicity, etc. Data labelling done via crowdsourcing, such as MS Turk, should include information about crowd participants, along with the instructions given for labelling.
- b. Peer-reviewed journals and conference organizers of the International Conference on Machine Learning or Neural Information Processing Systems should require standardized metadata for submissions. AI competition platforms, such as Kaggle, and data repositories, such as OpenML, should do the same.
- c. In collecting more diverse data, it is also important to go beyond convenient classifications—woman/man, black/white, etc.—which fail to capture the complexities of (trans)gender and ethnic identities (Bivens, 2017).
Developing methods to algorithmically detect and remove bias
It is important to be able to detect when an algorithm is potentially biased. Several groups are developing tools for this purpose.
- a. In one case, researchers carefully curated a gender and skin phenotype-balanced image benchmark dataset and labelled images by skin type. They then used this dataset to evaluate the accuracy of commercial gender classifiers, with resulting discrepancies as discussed above (Buolamwini & Gebru, 2018).
- b. To identify the gender biases in word embeddings discussed above, researchers developed geometry-based techniques. They then developed an algorithm to de-bias such embeddings, e.g. such that babysitter would be as equally close to “grandfather” as to “grandmother” (Bolukbasi, T. et al., 2016). Other researchers applied the standard Implicit Association Test to word embeddings to demonstrate that they contain many human-like biases (Caliskan et al., 2017). Still, others have developed a gender-neutral variant of GloVe (Zhao, 2018). For images, researchers first showed that training algorithms can amplify biases present in the training data and then developed a technique to reduce this amplification (Zhao et al., 2017).
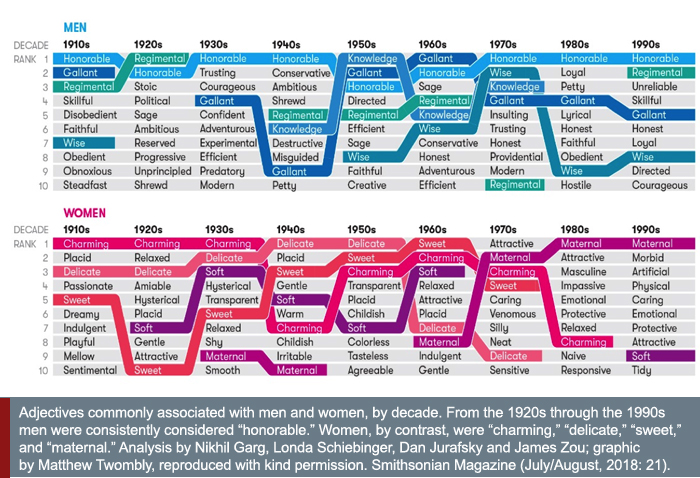
- c. Similar techniques can also be used to study historical stereotypes and biases in society at large. Researchers used geometry-based metrics for word embeddings trained on text data over 100 years to identify changes in historical gender and ethnic biases (Garg et al., 2018). Similar methods may be used to compare biases in texts today.
Such bias detection and reduction techniques are also necessary for other domains, such as criminal justice (e.g., estimating defendant risk and making bail decisions, or for sentencing), loans and other financial matters, and hiring. However, in such areas, careful attention must be paid to the exact definition of unlawful bias and of the consequences of various mitigation techniques. Such applications are part of a growing research area that requires interdisciplinary collaborations.
- a. One well-studied approach is to specify a fairness definition, e.g., that the model is equally accurate across groups, and then constrain the algorithm so that it follows the definition (Dwork et al., 2012; Hardt et al., 2016; Corbett-Davies et al., 2017). Similarly, one could post-process the results from an algorithm to be fair (Hébert-Johnson et al., 2017). Defining fairness in such domains, however, has proven to be a significant challenge (Kleinberg et al., 2017).
- b. One further challenge is identifying which groups should be protected and then developing an efficient algorithm that is fair to all such groups. Recent work on AI audit has made progress in automatically identifying subgroups where an algorithm might be biased, and to reduce such biases. The auditor, which itself is a machine learning algorithm, is able to identify bias even without explicit annotation of the sex/race of individuals (Kim et al., 2018).
Gendered Innovation 3: Systemic Solutions
As we strive to improve the fairness of data and AI, we need to think carefully about appropriate notions of fairness. Should data, for example, represent the world as it is, or represent a world we aspire to—i.e., a world that achieves social equality? Who should make these decisions? Computer scientists and engineers working on problems? Ethics teams within companies? Government oversight committees? If computer scientists, how should they be educated?
Creating an AI that results in both high-quality techniques and social justice requires a number of important steps. Here we highlight four:
- 1. Attend to infrastructure issues Attempts to create fairness are complicated by the need to understand how bias is embedded in institutional infrastructures and social power relations. Unless carefully studied, structural bias is often invisible to social actors—whether humans or algorithms. Wikipedia, for example, seems a good data source. Information rich, it is the fifth most used website in the world. But there are structural problems: entries on women constitute less than 30 percent of biographical coverage, link more often to articles on men than vice-versa, and include disproportionately high mention of romantic partners and family (Wagner et al., 2015; Ford & Wajcman, 2017). These asymmetries may derive from the fact that globally women account for less than 20 percent of Wikipedia’s editors (Wikimedia, 2018).
- 2. Rigorous social benefit review. The Asilomar Conference 2017 set out 23 principles for Beneficial AI (https://futureoflife.org/ai-principles/). We now need to develop review mechanisms designed to achieve these principles. One organization working toward this ends is Fairness, Accountability, and Transparency in Machine Learning (https://www.fatml.org). Several governmental reports have addressed the issue (Executive Office of the President, 2016; CNIL, 2017).
- 3. Create interdisciplinary and socially diverse teams. New initiatives, such as the Stanford Human-Centered AI Institute; the Fairness, Accountability, and Transparency in Machine Learning Organization; and others are bringing together interdisciplinary teams of computer scientists, lawyers, social scientists, humanists, medical, environmental, and gender experts to optimize fairness in AI. This type of cognitive and social diversity also leads to creativity, discovery, and innovation (Nielsen et al., 2017).
- 4. Integrate social issues into the core CS curriculum. Computer science students should graduate equipped with the basic conceptual tools for analyzing gender and ethnicity as well as the broader social impact of their work. We recommend that social issues be integrated into core CS courses —at both the undergraduate and graduate levels—alongside introductions to algorithms.
Conclusion
Artificial intelligence is poised to transform economies and societies, change the way we communicate and work, and reshape governance and politics. We humans have created long enduring social inequalities; equipped with new tools, we have the opportunity to engineer fairness across and within cultures and thereby enhance the quality of life for women, men, and gender-diverse people worldwide.Note: Some materials in this case study draw from Zou & Schiebinger (2018).
Works Cited
Angwin, J., & Larson, J. (2016, May 23). Bias in criminal risk scores is mathematically inevitable, researchers say. Propublica https://www.propublica.org/article/bias-in-criminal-risk-scores-is-mathematically-inevitable-researchers-say
Bivens, R. (2017). The gender binary will not be deprogrammed: Ten years of coding gender on Facebook. New Media & Society, 19(6), 880-898.
Bolukbasi, T., Chang, K. W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. Advances in Neural Information Processing Systems, 4349-4357.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. Conference on Fairness, Accountability and Transparency, 77-91.
Caliskan, A., Bryson, J., & Narayanan, N. (2017). Semantics derived automatically from language corpora contain human-like biases. Science 356 (6334), 183-186.
Corbett-Davis, S., Pierson, E., Feller A., Goal S., & Huq A. (2017). Algorithmic decision making and the cost of fairness. Conference on Knowledge Discovery and Data Mining.
Commission Nationale Informatique & Libertés (CNIL). (2017). How Can Humans Keep the Upper Hand: Ethical Matters Raised by Algorithms and Artificial Intelligence. French Data Protection Authority.
Datta, A., Tschantz, M. C., & Datta, A. (2015). Automated experiments on ad privacy settings. Proceedings on Privacy Enhancing Technologies, 2015 (1), 92-112.
Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012). Fairness through awareness. Proceedings of the 3rd innovations in theoretical computer science conference, 214-226. ACM.
Esteva, A., Kuprel, B., Novoa, R. A., Ko, J., Swetter, S. M., Blau, H. M., & Thrun, S. (2017). Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542 (7639), 115-126.
Executive Office of the President, Munoz, C., Director, D. P. C., Megan (US Chief Technology Officer Smith (Office of Science and Technology Policy), & DJ (Deputy Chief Technology Officer for Data Policy and Chief Data Scientist Patil (Office of Science and Technology Policy) (2016). Big Data: A Report on Algorithmic Systems, Opportunity, and Civil Rights. Executive Office of the President.
Ford, H., & Wajcman, J. (2017). ‘Anyone can edit’, not everyone does: Wikipedia’s infrastructure and the gender gap. Social studies of science, 47(4), 511-527.
Garg, N., Schiebinger, L., Jurafsky, D., & Zou, J. (2018). Word embeddings quantify 100 years of gender and ethnic stereotypes. Proceedings of the National Academy of Sciences, 115(16), E3635-E3644.
Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J. W., Wallach, H., Daumeé III, H., & Crawford, K. (2018). Datasheets for datasets. arXiv preprint arXiv:1803.09010.
Hardt, M., Price, E., & Srebro, N. (2016). Equality of opportunity in supervised learning. In Advances in neural information processing systems, 3315-3323.
Hébert-Johnson, U., Kim, M. P., Reingold, O., & Rothblum, G. N. (2017). Calibration for the (computationally-identifiable) masses. arXiv preprint arXiv:1711.08513.
Kim, Michael P., Amirata Ghorbani, and James Zou. Multiaccuracy: Black-Box Post-Processing for Fairness in Classification. arXiv preprint arXiv:1805.12317 (2018).
Kleinberg, J., Lakkaraju, H., Leskovec, J., Ludwig, J., & Mullainathan, S. (2017). Human decisions and machine predictions. The Quarterly Journal of Economics, 133 (1), 237-293.
Kleinberg J., Mullainathan, S., Raghavan, M., (2017). Inherent trade-offs in the fair determination of risk scores. In Proceedings of Innovations in Theoretical Computer Science (ITCS).
MIT Media Lab (2018). http://datanutrition.media.mit.edu
Nielsen, M. W., Andersen, J. P., Schiebinger, L., & Schneider, J. W. (2017). One and a half million medical papers reveal a link between author gender and attention to gender and sex analysis. Nature Human Behaviour, 1(11), 791.
Popejoy, A. B., & Fullerton, S. M. (2016). Genomics is failing on diversity. Nature, 538(7624), 161-164.
Prates, M. O., Avelar, P. H., & Lamb, L. (2018). Assessing gender bias in machine translation—a case study with Google Translate. arXiv preprint arXiv:1809.02208.
Schiebinger, L., Klinge, I., Sánchez de Madariaga, I., Paik, H. Y., Schraudner, M., and Stefanick, M. (Eds.) (2011-2018). Gendered innovations in science, health & medicine, engineering and environment, engineering, machine translation.
Shankar, S., Halpern, Y., Breck, E., Atwood, J., Wilson, J., & Sculley, D. (2017). No classification without representation: assessing geodiversity issues in open data sets for the developing world. arXiv preprint arXiv:1711.08536.
Sweeney, L. (2013). Discrimination in online ad delivery. Queue, 11(3), 10.
Wagner, C., Garcia, D., Jadidi, M., & Strohmaier, M. (2015, April). It’s a Man’s Wikipedia? Assessing Gender Inequality in an Online Encyclopedia. ICWSM, 454-463.
Wikimedia (2018), personal communication.
Zhao, J., Wang, T., Yatskar, M., Ordonez, V. & Chang, K.-W. (2017). Men also like shopping: reducing gender bias amplification using corpus-level constraints. arXiv preprint arXiv:1707.09457.
Zhao, J., Zhou, Y., Li, Z., Wang, W., & Chang, K. W. (2018). Learning Gender-Neutral Word Embeddings. arXiv preprint arXiv:1809.01496.
Zou, J. & Schiebinger, L. (2018). Design AI that’s fair. Nature, 559(7714), 324-326.