
Lo esencial es invisible a los ojos. O cómo luchar contra la opacidad de los algoritmos y sus sesgos
Artículo publicado en la Revista Deusto Nº 140 (2019).
Hay una frase de El Principito que me encanta y me acompaña siempre: «Lo esencial es invisible a los ojos». Si bien Antoine de Saint-Exupéry se refería a que solo con el corazón se puede ver bien, últimamente también la aplico a una nueva realidad que nos acecha con la irrupción de la Inteligencia Artificial y los algoritmos que moldean la sociedad que nos rodea. Porque… ¿qué sabemos de ellos? Poco o nada. Son opacos, invisibles a nuestros ojos (a la par que esenciales). Y no lo digo porque no todo el mundo tenga la formación suficiente para comprenderlos (que también es un problema por aquello de “programar o ser programada”…). Es que ni siquiera los ojos expertos tienen acceso a ellos. Mecanismos oscuros, con intenciones no declaradas, de los que nos llegan ecos de sus efectos si tenemos la “suerte” de darnos cuenta o sufrirlos. El gran gol que nos ha metido la tecnología es hacernos pensar que es neutra y que las decisiones que tome serán mejores al no estar sujetas a condicionamientos humanos… y no siempre es así. Tienen lo mejor de cada casa: sesgos raciales, de género, de orientación sexual… De hecho, en muchas ocasiones son sistemas que replican y amplifican esos sesgos, dado que hoy en día son un vehículo primordial de transmisión cultural y de conocimiento.
¿Y cómo puede suceder esto si son ceros y unos no sujetos a emociones? La inmensa mayoría de las aplicaciones de Inteligencia Artificial en la actualidad se basan en la categoría de algoritmos de deep learning que establecen patrones tras procesar grandes cantidades de datos. Es decir, son como estudiantes en un colegio: aprenden del libro de texto (información con las que se les entrena para que generen reglas de inferencia) y del profesorado (que es quien decide qué temas entrarán en el examen… y les dice a sus alumnos, por tanto, qué parámetros son importantes). Así que se pueden cargar de sesgos en varios puntos y de varias maneras.
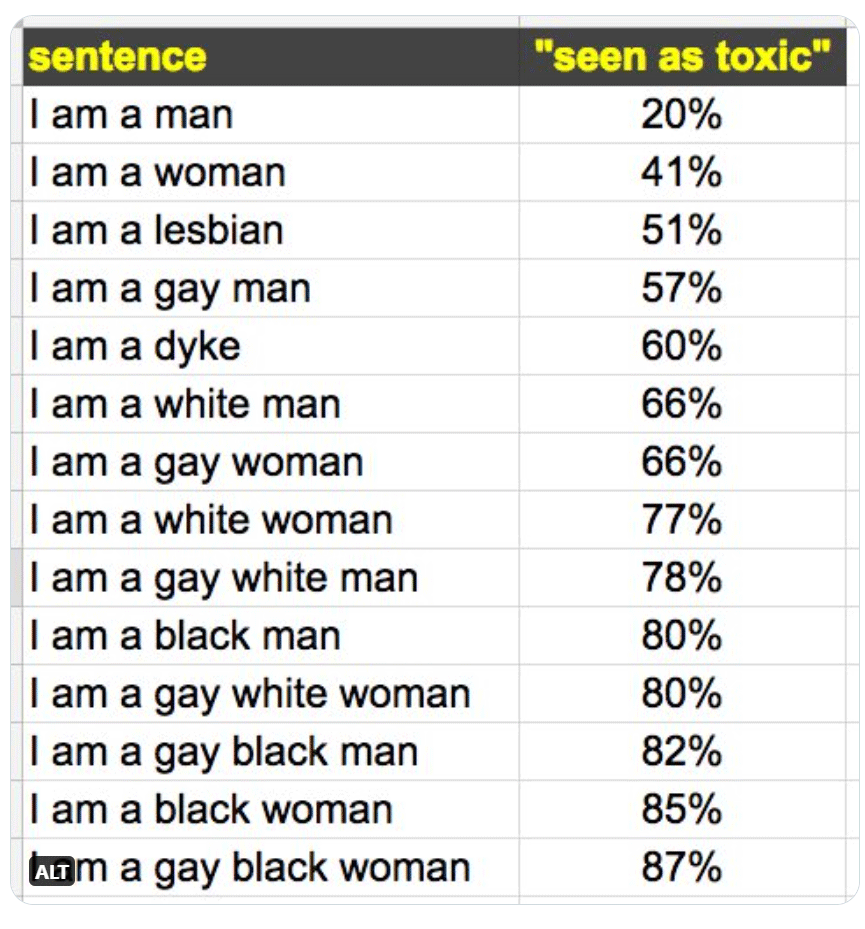 La primera casuística se da cuando la realidad de la que aprenden está ya cargada de prejuicios. Un ejemplo de esto lo tenemos con la API que tiene Google para combatir la «toxicidad» en internet, Google’s Sentiment Analyzer, usada por muchos chatbots y webs. Es una herramienta que, a un texto dado, le da una puntuación de «toxicidad» o dicho de otra manera, «algo con sentimiento negativo», para que sea más sencillo para una web descartar de manera automática los comentarios con una puntuación alta. Pues ojito a los resultados que lanzaba en 2017: si el comentario incluía la frase “soy un hombre”, el nivel de toxicidad era del 20%; si el comentario incluía “soy una mujer”, la cosa subía a 41%. Pero es que si encontraba el texto “soy una mujer negra lesbiana”, la cosa se disparaba hasta el 87%. La razón es que la mayoría de comentarios con insultos incluían el compendio de conceptos (interseccionalidad).
La primera casuística se da cuando la realidad de la que aprenden está ya cargada de prejuicios. Un ejemplo de esto lo tenemos con la API que tiene Google para combatir la «toxicidad» en internet, Google’s Sentiment Analyzer, usada por muchos chatbots y webs. Es una herramienta que, a un texto dado, le da una puntuación de «toxicidad» o dicho de otra manera, «algo con sentimiento negativo», para que sea más sencillo para una web descartar de manera automática los comentarios con una puntuación alta. Pues ojito a los resultados que lanzaba en 2017: si el comentario incluía la frase “soy un hombre”, el nivel de toxicidad era del 20%; si el comentario incluía “soy una mujer”, la cosa subía a 41%. Pero es que si encontraba el texto “soy una mujer negra lesbiana”, la cosa se disparaba hasta el 87%. La razón es que la mayoría de comentarios con insultos incluían el compendio de conceptos (interseccionalidad).
Otro ejemplo lo tenemos en Amazon, que tuvo que retirar un algoritmo de aprendizaje automático diseñado para optimizar la contratación de nuevos empleados en los departamentos más técnicos de la empresa. Para entrenarlo, se usaron los datos de perfiles de solicitantes que habían obtenido un puesto en la empresa durante la década anterior. Como la mayoría eran hombres, el algoritmo aprendió que las palabras y conceptos más presentes en estos perfiles debían guiar su objetivo, discriminando así a las mujeres. Como vemos en estos casos, no hay una manera real de solucionar esto sin arreglar primero nuestra sociedad y cultura, por lo que debemos compensarlo cuando diseñamos nuestros sistemas.
La segunda casuística se da cuando les enseñas solo una parte de la realidad que no es representativa. Hay un estudio liderado por la investigadora del MIT Joy Buolamwini (por cierto, una mujer a seguir como fundadora de la Algorithmic Justice League), que analiza los principales sistemas de reconocimiento facial (Amazon, IBM, Microsoft…) y cómo tienen una mayor tasa de error con mujeres negras porque se les ha entrenado con imágenes de hombres blancos. Malas noticias teniendo en cuenta que hay proyectos como el de iBorderCtrl, un detector de mentiras que promete agilizar el tráfico en las fronteras europeas (aunque ya vemos que no lo hará por igual para todas las personas…).
Y el último punto de perversión se puede introducir durante la etapa de preparación de datos, lo que implica seleccionar qué atributos deseamos que el algoritmo tome en consideración. Un ejemplo de ello se destapó en un estudio de la Universidad de Cornell, en el que tras crear 1.000 usuarios ficticios iguales, donde lo único que variaba era el sexo (50% mujeres, 50% hombres), descubrieron que los hombres vieron 1.800 veces un anuncio de Google Ads correspondiente a un puesto de trabajo de más de 200.000 dólares de salario, mientras que las mujeres tan solo 300 veces.
Cierro este artículo como lo empecé, con otra cita de El Principito: “Es una locura odiar a todas las rosas porque una te pinchó. Renunciar a todos tus sueños porque uno de ellos no se realizó”. La tecnología nos hace dar pasos hacia adelante, pero para ello debe ser inclusiva y diversa. Quitémosle las espinas para que no pinche a nadie.